
Traemos la segunda parte del blog post «Escalabilidad de IOTA Parte 1 – Una introducción al sharding» que posteamos el Martes pasado escrito por Hans Moog. En esta oportunidad nos sumergimos en cómo sería el funcionamiento de la Tangle con sharding para un mejor rendimiento de los nodos y por supuesto para otorgarle a la Tangle la característica de escalabilidad al ser usada por miles de millones de dispositivos interconectados.
Si bien ya aclaramos de que estos ejemplos no son los definitivos a implementarse, sirven para dar un pantallazo a los requerimientos de la Tangle para funcionar con shards.
Los dejamos con la traducción de «Scaling IOTA Part 2 – Untangling the Tangle» para que sigamos aprendiendo sobre este feature fundamental para la escalabilidad de las DLTs.
Para resolver los problemas mencionados en la primera parte de esta serie de blogs, necesitamos una forma completamente diferente de sharding.
En las siguientes secciones, haremos una introducción paso a paso a los conceptos que permitirán a IOTA escalar infinitamente el número de nodos, sin poner en peligro la seguridad en las primeras etapas de la adopción o romper con los «choques de suministro» en los requisitos de rendimiento.
La Tangle se fragmenta automáticamente
El Tangle no está limitado por un tamaño de bloque y cualquiera puede adjuntar siempre nuevas transacciones sin depender de nada más que de los dos eventos anteriores a los que hace referencia. Esto significa que el Tangle esencialmente nunca está lleno y puede contener un número arbitrario de transacciones.
Si el rendimiento de la red supera la capacidad de procesamiento de los nodos, éstos verán y procesarán diferentes transacciones dependiendo del lugar de la red en el que se encuentren y, por tanto, también verán diferentes tangles. Los nodos con capacidades de procesamiento similares, que estén cerca unos de otros, tendrán una percepción similar.
Cada nodo validará su parte respectiva del DAG que consiste en un subconjunto de todas las transacciones existentes. Esta es la definición misma de sharding: «Dividir las tareas y hacer que cada nodo sólo realice un subconjunto de la cantidad total de trabajo».
La siguiente imagen muestra el aspecto de una tangle de sharding natural (la mitad de las transacciones son procesadas por la mitad de los nodos):
Este proceso de división puede producirse de forma recurrente, es decir, el shard 1 se divide en otros shards cuando los nodos no pueden procesar todas las transacciones restantes. Los distintos segmentos de la red se dividirán en diferentes momentos, dependiendo del rendimiento real y de forma más o menos instantánea, sin tener que entablar complicadas negociaciones sobre cuándo y dónde dividir. Simplemente depende de las transacciones que los nodos puedan procesar (enfoque centrado en el agente).
Una vez que la carga disminuye, las diferentes tangles son, en teoría (ver problemas más adelante), capaces de volver a unirse, lo que da como resultado un sistema capaz de reaccionar dinámicamente a las diferentes condiciones de la red y a la creciente adopción.
Problemas de este enfoque
Aunque esta solución es extremadamente sencilla y, en teoría, permite a la red escalar hasta una cantidad arbitraria de transacciones por segundo, también tiene algunos problemas muy graves:
- Los nodos no perciben de qué parte de la tangle son responsables. En consecuencia, los usuarios tendrían dificultades para saber qué nodo elegir al intentar acceder a sus fondos.
- Resulta difícil que los diferentes shards interactúen, ya que no hay una percepción objetiva sobre qué shards existen.
- Dado que las diferentes tangles comparten el mismo historial pero no los mismos validadores, se podrían gastar dos veces los fondos que se recibieron antes de la división, en cada shard por separado:
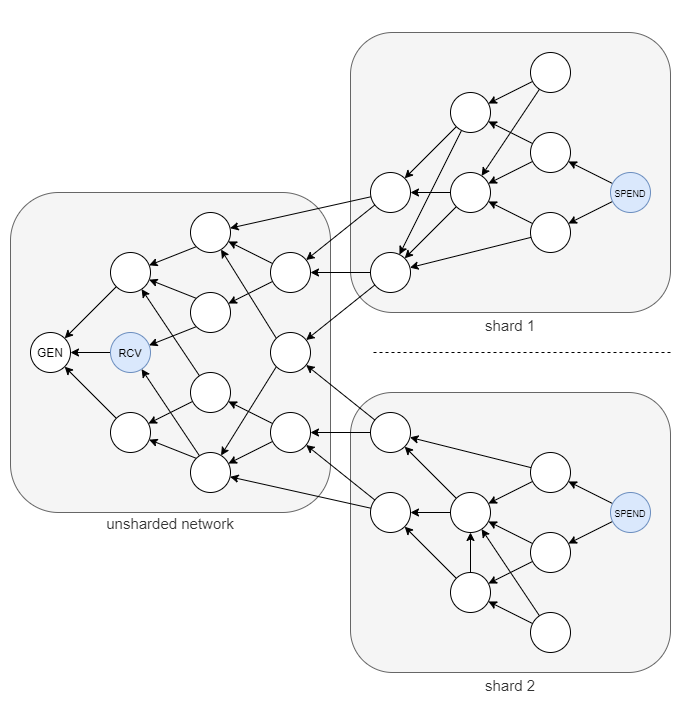
Este problema de doble gasto es bastante grave, ya que incluso impide que las tangles se vuelvan a unir (una vez que la carga baja), lo que socava todo el potencial de la solución.
La razón de estos problemas no es la estructura del DAG en sí misma (como se afirma en este vídeo de RADIX), sino el hecho de que el Tangle se fragmenta esencialmente de forma totalmente incontrolada y aleatoria.
Cómo resolver los problemas mencionados
Para resolver estos problemas tenemos que encontrar una manera de que los nodos se shardeen de forma no aleatoria y determinista. Esto significa que esencialmente necesitamos encontrar un mecanismo que nos permita asociar los nodos y sus transacciones a una determinada ubicación en la red shardeada.
Para conseguirlo, hacemos que cada nodo y cada transacción lleven un marcador que define a qué sharding pertenecen (incluso antes de que evolucione ningún shard). Cuando surge la necesidad de dividirse, el DAG se divide y el estado del ledger se divide con él.
Veamos el mismo ejemplo, pero esta vez con cada transacción que lleva un marcador (azul o rojo):
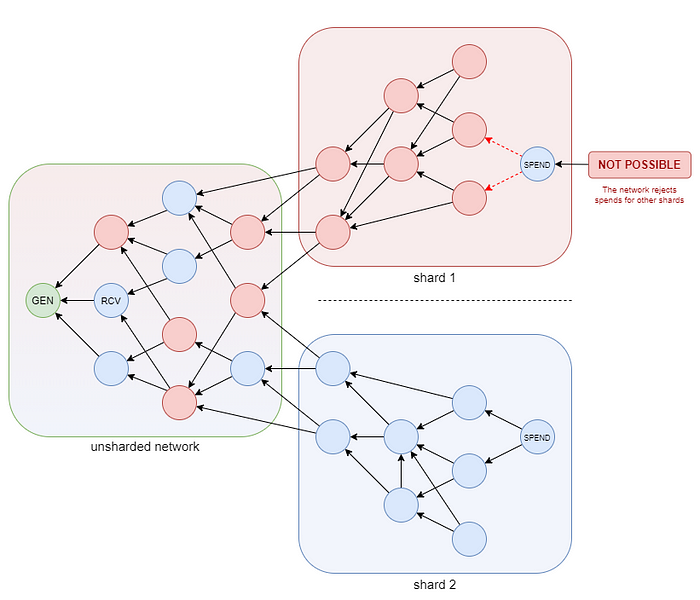
Inicialmente, las transacciones de los distintos shards están «enredadas», pero después de que la tangle se divida, los nodos rojos sólo harán un seguimiento de los saldos y transacciones rojas y los azules sólo de su parte respectiva. Este sencillo mecanismo elimina la posibilidad de gastar dos veces los fondos antiguos sin introducir una forma complicada de comunicación entre shards. Cada shard tiene una determinada jurisdicción de la que es responsable y un usuario que intente gastar fondos azules en el shard rojo será simplemente ignorado. Este mecanismo se llama state shard.
En el ejemplo hemos utilizado colores, pero los marcadores son en realidad números que pueden representarse con una máscara de bits, lo que permite que la tangle se desglose con una frecuencia arbitraria (un marcador de 64 bits nos permitiría, por ejemplo, crear más de 9 quintillones de shards).
El marcador de shard se convierte en algo así como el ADN de fragmentación de una transacción que lleva toda la información que necesita, para determinar su futura posición en un DAG adulto. En su estado infantil, esta información estará latente, pero permitirá al Tangle fragmentar de forma fiable tan pronto como surja la necesidad.
Dado que los estados del ledger de ambas ramas nunca pueden entrar en conflicto, estos shards pueden incluso volver a unirse en un momento posterior cuando la carga disminuya.
Una superposición lógica del «mundo real»
Los marcadores de shards resuelven todos los problemas mencionados, pero además nos proporcionan una herramienta muy potente que nos permite diseñar una disposición de shards que refleje el mundo real como una forma de mapeo lógico superpuesto, lo que en última instancia significa que podemos dar a los números que representan los marcadores de shards un determinado significado.
Dado que estamos diseñando un protocolo para el Internet de las Cosas, tiene mucho sentido utilizar un mapeo geográfico en el que los marcadores de shard se traducen en ciertas coordenadas en este planeta. De este modo, los nodos que estén físicamente cerca unos de otros formarán parte del mismo shard.
Esto no sólo reducirá las latencias de la red dentro de un shard, sino que también reducirá la cantidad de comunicación entre shards a un mínimo absoluto, ya que la mayor parte de la actividad económica ocurre localmente:
- Un coche compra electricidad en una estación de carga cercana.
- La gente compra pizza en la pizzería de la esquina.
- y así sucesivamente…
Este mapa geográfico superpuesto es, por tanto, una muy buena aproximación a las relaciones económicas de una determinada región.
Además, este uso de un mapa geográfico es una buena manera de tratar las divisiones de la red a gran escala. Si un segmento de la red se desconecta debido, por ejemplo, a cosas como la Tercera Guerra Mundial, entonces nadie puede gastar fondos chinos en los Estados Unidos y viceversa. Por lo tanto, las dos redes separadas tienen más posibilidades de volver a unirse una vez resuelta la división.
Si los marcadores shard resuelven todos los problemas mencionados… ¿hemos terminado? Todavía no. Todavía quedan algunos problemas por resolver:
Antes de introducir los marcadores de shard, los nodos se dividían automáticamente en función de sus propias capacidades de procesamiento. Sin embargo, este mecanismo ya no tiene sentido, ya que intentamos que los nodos se fragmenten en función de su pertenencia a una determinada jurisdicción.
Por lo tanto, los nodos deben tener alguna forma de consenso sobre cuándo y dónde fragmentar. Se trata de un problema complicado, sobre todo porque los nodos tienen capacidades de procesamiento completamente diferentes y, por tanto, percepciones distintas sobre cuándo ha llegado el momento de dividir.
Desenredando la Tangle
Dado que queremos mantener los mecanismos simples y no queremos introducir otro mecanismo de consenso sobre la tangle, tenemos que encontrar un enfoque diferente para tratar este problema.
Si nos fijamos en los marcadores de los shards y en lo que realmente «significa» tener subtángulos separados para cada shard, nos damos cuenta rápidamente de que nos da exactamente un beneficio: los nodos que procesan, por ejemplo, el shard rojo, tienen una forma de identificar, descargar y procesar sólo las transacciones rojas, sin que se enreden con las transacciones de otros shards.
Si el único propósito de tener subtítulos separados es separar las transacciones relacionadas, entonces podemos lograr lo mismo modificando la selección de puntas de la siguiente manera:
Al adjuntar una nueva transacción que lleva un marcador de shard X, entonces elegimos una punta como la rama que tiene un marcador de shard Y donde Y ≤ X y un tronco que tiene un marcador de shard Z donde Z ≥ X.
Lo que obtenemos es un DAG que está pre-particionado según los marcadores de la Tangle. Seguir la rama referenciada nos permitirá descubrir transacciones con un marcador igual o menor y seguir el tronco nos permitirá descubrir transacciones con un marcador igual o mayor – ver imagen (usando colores en lugar de números para los marcadores):
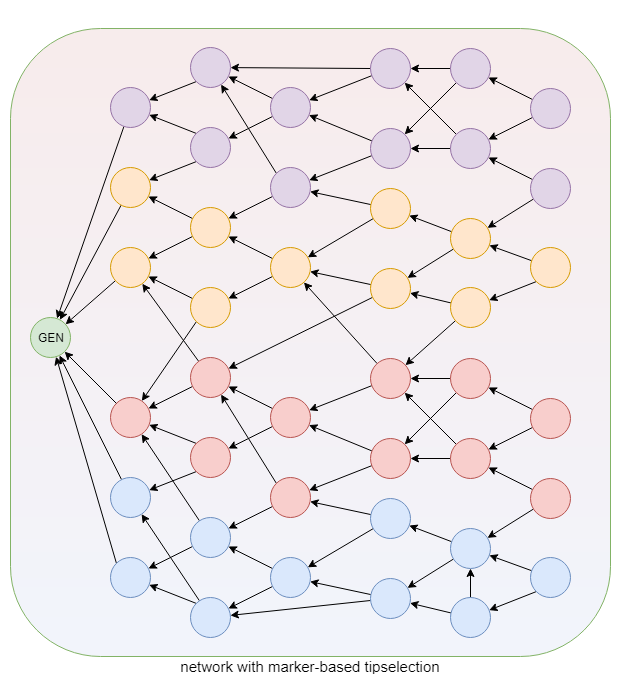
Aunque el gráfico ya no está dividido en ramas distintas, todavía podemos identificar, verificar y solidificar las transacciones que llevan marcadores iguales de la misma manera que si estuvieran realmente divididas.
Al solidificar la tangle, los nodos dejarán de solicitar las transacciones que falten, en cuanto lleguen a un marcador que no les interese, y se limitarán a considerar estas transacciones como sólidas. Dado que el «estado del ledger azul» sólo se verá afectado por las «transacciones azules«, ignorar las transacciones rojas no tendrá ningún efecto adverso en un nodo azul.
Shard fluido
La forma descrita de desenredar la tangle no sólo elimina la necesidad de llegar a un consenso sobre cuándo y dónde dividir, sino que también da a los nodos total libertad para elegir qué parte del DAG resultante les interesa y qué parte del DAG quieren ver y procesar sin necesidad de un diseño de sharding predeterminado.
Los dispositivos IoT con recursos limitados pueden supervisar una parte más pequeña del DAG que los nodos más potentes. Por lo tanto, los shards ya no serían trozos aislados de datos, sino regiones continuas, en las que los nodos pueden validar diferentes partes según su interés (ubicación en el mundo real); véase la imagen:

Ejemplo: Una persona que viva entre Berlín Este y Oeste, podría decidir «seguir» la mitad de Berlín Este y la mitad de Berlín Oeste, mientras que una persona que viva en el centro de Berlín Oeste podría decidir seguir sólo Berlín Oeste.
También podemos ajustar el tamaño de la franja supervisada en función de los requisitos de rendimiento de la red cambiando el radio de observación.
Ejemplo: Los nodos de una región con muy poca actividad económica podrían permitirse supervisar una «tajada» del DAG mucho mayor que los nodos que operan en una zona densamente poblada con un número relativamente mayor de transacciones.
Utilizando una cola de prioridad para las transacciones recibidas -que ordena las transacciones recibidas según su distancia a la ubicación de un nodo en la red-, los nodos reducirán automáticamente su radio de percepción cuando se sobrecarguen, filtrando las transacciones de los nodos que estén demasiado lejos. De este modo, reaccionarán instantáneamente a las diferentes necesidades de rendimiento sin tener que renegociar una nueva disposición de shard o utilizar tarifas para decidir qué transacciones ejecutar. La solución se centra en los agentes y nos permite reaccionar instantáneamente a las diferentes cargas de la red.
Conclusión
Hemos introducido unos cuantos cambios muy sencillos en el funcionamiento de la tangle. Estos cambios nos permiten desenredar las transacciones en el DAG y agruparlas según su participación en los shards correspondientes.
En lugar de ejecutar simplemente muchas Tangles en paralelo (como las blockchains), esta nueva forma de sharding fluida nos permite seguir utilizando una gran Tangle continua que abarca todo el mundo y sigue siendo capaz de procesar una cantidad arbitraria de transacciones por segundo.
Al principio, cuando la adopción es todavía baja, lo más probable es que la mayoría de los nodos vean y procesen todas las transacciones, pero en cuanto la adopción crezca y los requisitos de rendimiento superen las capacidades de procesamiento de los nodos, veremos cómo éstos van disminuyendo poco a poco su radio de percepción para poder manejar la mayor carga.
En la tercera parte de esta blog, que se publicará en breve, explicaré cómo van a funcionar las transacciones entre shards distantes y cómo el hecho de tener una tangle continua nos permite implementar un mecanismo similar al de una bacon chain, pero sin una bacon chain, desbloqueando una verdadera escalabilidad «infinita» (con el número de nodos).






 se une al ecosistema de Assembly")














