

Este es el primero de una serie de artículos que explican los protocolos de consenso descritos en IOTA Coordicide.
El objetivo principal de esta serie es mantener a la comunidad informada sobre los resultados de investigaciones recientes y también explicar preguntas de investigación interesantes que tengan buenas posibilidades de ser financiadas por el Coordicide Grant. Como verás, el tema es bastante amplio y hay muchas conexiones y dependencias con otras partes del proyecto Coordicide.
Ante esta complejidad, trataremos de explicar sólo unos pocos puntos a la vez y nos centraremos en las preguntas que se están investigando actualmente. Dicho esto, tomemos nota de que IOTA ya tiene todos los ingredientes clave para una solución eficiente y segura para el Coordicide.
Las cuestiones pendientes se refieren, por ejemplo, a la optimización de la solución:
- Aumento de la seguridad
- Aumento de la sostenibilidad (por ejemplo, disminución de la complejidad de los mensajes, disminución del PoW).
- Aumentar el TPS
- Reducción del tiempo hasta llegar al concenso
- Aumentar la flexibilidad de la aplicación para hacer frente a los retos del futuro.
Ahora, vayamos al grano y entendamos de qué se trata este «consenso».
¿Por qué el consenso?
Los algoritmos de consenso distribuidos permiten que los sistemas en red se pongan de acuerdo sobre un estado u opinión requeridos en situaciones en las que la toma de decisiones descentralizada es difícil o incluso imposible.
La informática distribuida es intrínsecamente poco fiable. Lograr el consenso permite que un sistema distribuido funcione como una sola entidad. La importancia de este reto radica en su omnipresencia, en la que la tolerancia a los fallos es uno de los aspectos más fundamentales.
Ejemplos comunes incluyen: sistemas de archivos replicados, sincronización de relojes, asignación de recursos, programación de tareas y por último, pero no menos importante, ledgers de contabilidad distribuida.
Los sistemas distribuidos forman un tema vasto y clásico de la informática y lo mismo ocurre con los protocolos de consenso asociados: ver Cómo funciona el consenso distribuido para una introducción elegante a este tema.
Los protocolos de consenso existentes son esencialmente los protocolos clásicos -por ejemplo, los basados en el PAXOS- y el reciente cambio de juego: el consenso de Nakamoto. Ambos protocolos tienen serias restricciones.
Los protocolos clásicos tienen una complejidad de mensaje cuadrática, requieren un conocimiento preciso de los miembros y son bastante frágiles contra las perturbaciones. El protocolo de Nakamoto, por otra parte, es robusto y no requiere membresías precisas. Sin embargo, se basa en el PoW, lo que conduce a problemas bien conocidos como las «carreras mineras» y la no escalabilidad.
Entonces, ¿cómo se logra el consenso en el Tangle de IOTA?
En primer lugar, recordemos el consenso de Nakamoto. Una idea brillante del consenso de Nakamoto es hacer que el consenso sea no determinista o probabilístico. En lugar de que todos los nodos del sistema (distribuido) acuerden la exactitud de un valor, acuerdan la «probabilidad» de que ese valor sea correcto.
El papel del líder en los protocolos de consenso tradicionales es asumido por el nodo que resuelve más rápidamente un determinado rompecabezas computacional; este ganador añade un nuevo bloque a la cadena de bloques. De esta manera, la red (distribuida) está construyendo la creciente cadena de bloques y acuerda la validez de la cadena más larga o de la cadena con mayor dificultad acumulativa.
Entonces, ¿por qué es probabilístico este consenso? Para saber si una determinada transacción se considerará válida, por ejemplo, en 100 días, tenemos que saber que la cadena más larga en 100 días contendrá esta transacción en particular.
En otras palabras, nos interesa la probabilidad de que la cadena más larga en 100 días contenga esta transacción. La probabilidad de que una transacción no sea revertida aumenta a medida que el bloque que contiene esta transacción se «hunde» más en la cadena.
En la cadena de bloques bitcoin, por ejemplo, se recomienda esperar hasta que una transacción esté a seis bloques de profundidad en la cadena de bloques. Después de esta profundidad, la probabilidad de que una transacción se revierta es muy baja.
Este efecto también se aplica al Tangle. Cuanto más profunda -o más «envuelta» por la Tangle- sea una transacción, más definitiva será. En la siguiente imagen, la transacción de color verde oscuro es validada por todas las transacciones de color verde claro. A medida que el número de transacciones en verde claro crece, la probabilidad de que la transacción en verde oscuro sea en el futuro Tangle converge a 1.
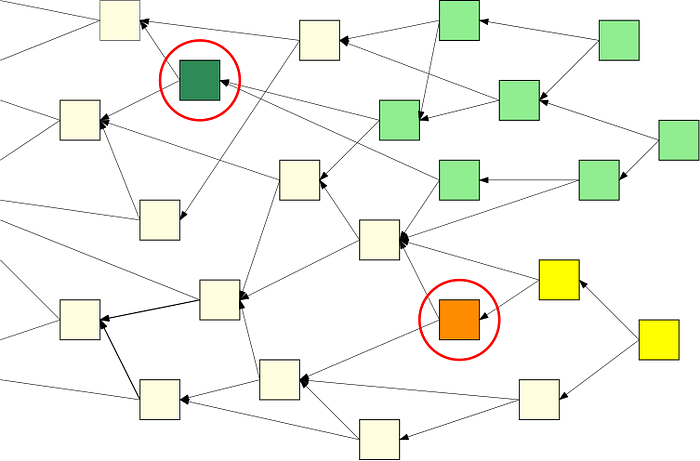
Pero espera, ¡Tangle es diferente a un blockchain! Aunque no se permite que la Blockchain contenga dos transacciones en conflicto, la Tangle puede contener temporalmente tales transacciones. Por lo tanto, puede ser que un jugador malicioso conecte dos transacciones conflictivas en diferentes partes del Tangle, como los cuadrados verde oscuro y naranja de la imagen de arriba.
Estas transacciones pueden «sobrevivir» en el Tangle durante un corto periodo de tiempo hasta que los nodos honestos detecten el conflicto. Una vez detectado el conflicto, los nodos deciden qué transacción elegir. En el ejemplo anterior, la transacción verde más oscura está «más envuelta» por la Tangle y debería ser aprobada por todos los nodos.
Para que la Tangle se convierta en un verdadero protocolo de consenso, tenemos que decidir sobre las transacciones en conflicto. Esa decisión debe tomarse utilizando un protocolo de consenso.
¿Caminamos en círculos por aquí? Afortunadamente no: Coordicide propone otros dos protocolos de consenso:
- el Fast Probabilistic Consensus (FPC) y
- el Cellular Consensus (CC)
El resto de este post estará dedicado a una breve introducción al FPC y a explicar cómo llegar a un consenso a la hora de decidir si una sola transacción es válida o no.
En un futuro artículo en el blog, abordaremos por qué esto es suficiente para llegar a un consenso en el nivel de Tangle y discutiremos la finalidad de las transacciones en el Tangle.
¿Qué es el FPC?
En términos elegantes, el FPC es un protocolo de consenso binario probabilístico sin líder de baja complejidad comunicacional que es robusto en una infraestructura bizantina – vea el artículo original de Serguei Popov y Bill Buchanan.
Veamos, a medida que avanzamos, qué significan realmente todos estos términos y empecemos por presentar una versión más ligera del FPC que sea fácil de implementar y que contenga la mayoría de las características importantes.
Suponemos que la red tiene n nodos indexados por 1,2,….,n. Cada nodo i tiene una opinión o estado. Denominamos s_i(t) por la opinión del nodo i en el momento t. Las opiniones toman valor en {0,1}; siendo la razón por la que hablamos de un consenso binario.
La idea básica es el voto por mayoría. En cada ronda, cada nodo consulta k nodos aleatorios y establece su opinión igual a la mayoría de los nodos consultados. Tan simple como eso! Sin embargo, esta votación por mayoría simple resulta ser frágil contra nodos defectuosos y atacantes maliciosos. Necesita un ingrediente adicional, de hecho una aleatoriedad adicional, para que sea robusto.
Más formalmente, en cada paso, cada nodo elige k nodos aleatorios C_i, consulta sus opiniones y calcula la opinión media
Denominamos ? ∊[0,1] el primer umbral que permite cierta asimetría en el protocolo, otro tema que abordaremos en un futuro próximo. Además, introducimos una «aleatoriedad adicional»; dejemos que U_{t}, i=1, 2,…. sean i.i.d. variables aleatorias con ley Unif(?, 1- ?) para algún parámetro ? ∊[0,1/2].
En cada momento, cada nodo i usa las opiniones de los nodos aleatorios k para actualizar su propia opinión:
y para t>0:
Es importante que en cada ronda un nodo consulte un conjunto aleatorio diferente de nodos y que las variables aleatorias U_t se actualicen también en cada ronda.
Introducimos una regla de terminación local para reducir la complejidad de la comunicación del protocolo. Cada nodo mantiene una variable de contador cnt que se incrementa en 1 si no hay cambio de opinión y que se fija en 0 si hay cambio de opinión.
Una vez que el contador alcanza un cierto umbral l, es decir, cnt≥1, el nodo considera que el estado actual es definitivo. Por lo tanto, el nodo ya no enviará ninguna consulta, pero responderá a las consultas entrantes. Los siguientes gráficos muestran las evoluciones típicas de la variable cnt para cada nodo con l=5, k=10 y opiniones iniciales del 90% de 1`s y 10% de 0`s.
En la imagen de la izquierda el protocolo no está perturbado, pero en la de la derecha el 20% de los nodos están tratando maliciosamente de convertir la mayoría de los nodos honestos. En ambos casos, eventualmente todos los nodos honestos coinciden en la mayoría inicial.
Queremos destacar la característica de los umbrales aleatorios comunes del FPC y referirnos a la Simulación del FPC para un primer análisis del FPC para varios tipos diferentes de ajustes de parámetros y estrategias de ataque.
Efecto de los umbrales aleatorios
La importancia de la incertidumbre en la guerra fue introducida por Carl von Clausewitz:
La guerra es el reino de la incertidumbre; tres cuartas partes de los factores en los que se basa la acción en la guerra están envueltos en una niebla de mayor o menor incertidumbre. Se requiere un juicio sensible y discriminatorio; una inteligencia hábil para olfatear la verdad.
– Carl von Clausewitz, 1873
¿Qué tiene que ver esto con los umbrales aleatorios en el FPC? En la mayoría simple, la votación de estos umbrales sólo sería igual a 0,5. Una estrategia de ataque fructífera podría ser mantener los η’s de los nodos honestos alrededor de 0.5 evitando una convergencia del protocolo (veremos un ataque tan exitoso más adelante). La idea de Popov y Buchanan era añadir «ruido» o «niebla» al sistema para aumentar la incertidumbre de información para los atacantes potenciales.
¿Por qué es tan importante todo esto? En una situación sin nodos maliciosos, la distribución de los η’s será similar a una distribución normal:
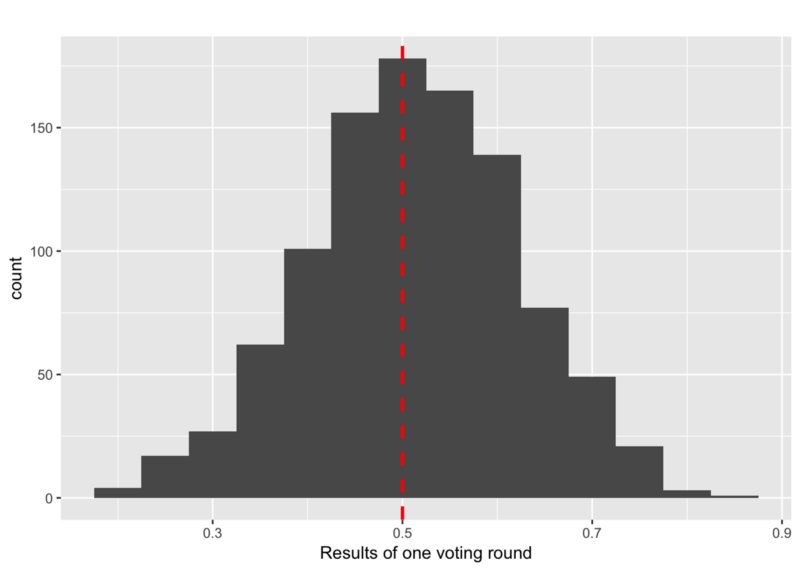
Ya en una situación no perturbada, las opiniones de los nodos honestos pueden estar cerca de una situación de 50:50. Sin embargo, los efectos aleatorios, causados por la votación al azar, finalmente conducen a la convergencia del protocolo. Esta situación es completamente diferente en una infraestructura bizantina.
Consideremos una estrategia de adversario que subdivida los nodos honestos en dos grupos de igual tamaño de opiniones diferentes que conduzcan a una distribución de los η entre nodos honestos como:
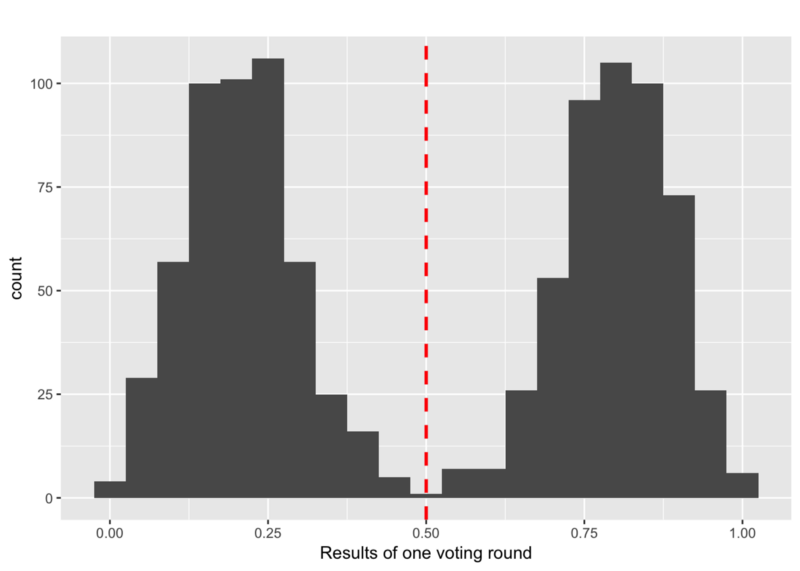
Entonces, ¿cómo puede un adversario lograr esto?
El adversario espera hasta que todos los nodos honestos hayan recibido opiniones de todos los demás nodos honestos. El adversario calcula entonces la mediana de estos η intermedios. Ahora, el adversario trata de mantener la mediana de los η cerca de 0.5 tratando de maximizar las variaciones de los η.
¿Cómo puede el FPC prevenir un ataque de este tipo? Sustituyendo el umbral determinístico (rojo, discontinuo) por umbrales aleatorios (azul, discontinuo). En el siguiente gráfico, cada línea azul representa un umbral aleatorio de una ronda determinada. Como estos umbrales son aleatorios, el adversario no puede prever cómo dividir los nodos honestos para mantener la situación de 50:50. La mejor manera es dividirlos entre el valor 0.5.
Sin embargo, una vez que una línea azul (en r3 en la imagen de abajo) está lo suficientemente lejos de la línea roja, el adversario pierde el control de los nodos honestos y el protocolo termina.
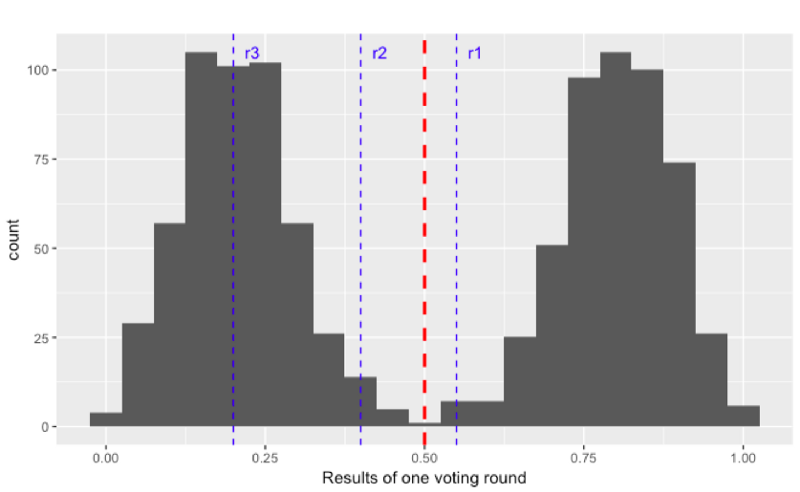
En la siguiente animación se puede ver el comportamiento y el resultado del protocolo cuando se aplica esta estrategia contradictoria sin aleatoriedad (umbral=0,5) y después de que se añade la aleatoriedad. Como puedes ver, el adversario consigue mantener los nodos en el limbo durante mucho tiempo. Pero lo que es peor, la red está dividida en su opinión, lo que conduce al fracaso de un acuerdo. Sin embargo, después de que se introduce la aleatoriedad adicional, el protocolo concluye rápidamente y en unidad.
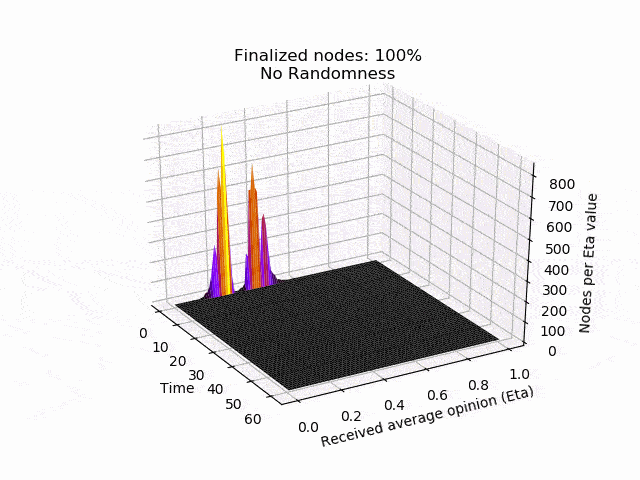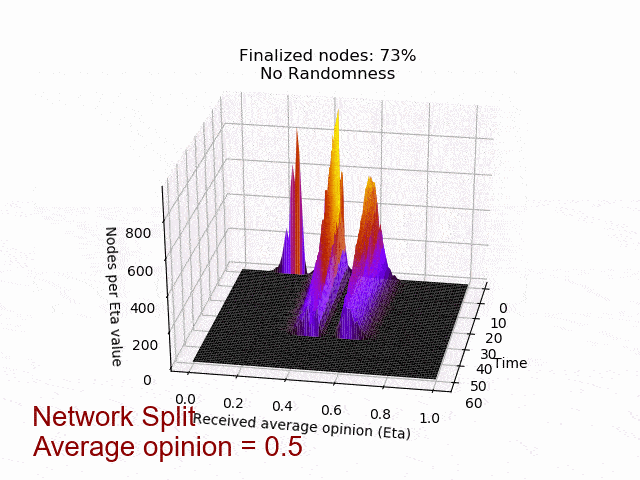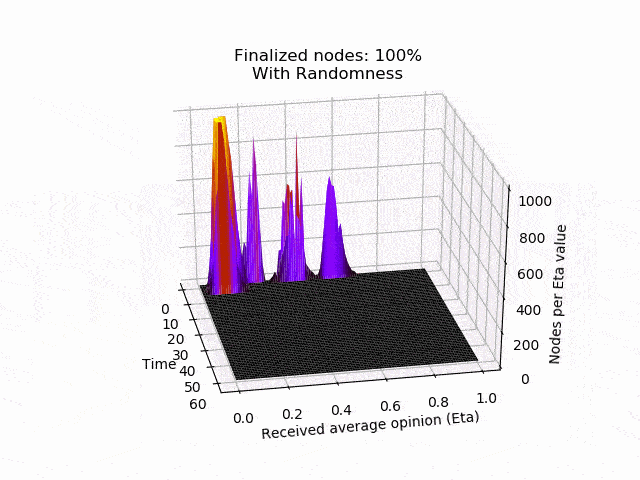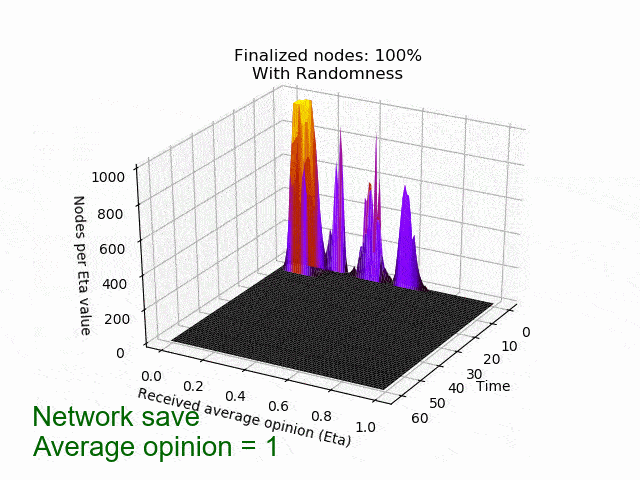
Trabajo en curso y próximos pasos
Por último – pero no menos importante – volvamos a algunos de los puntos en los que IOTA está trabajando actualmente y señalemos algunos ejemplos de futuras colaboraciones:
- Actualmente estamos realizando simulaciones exhaustivas para estudiar varias estrategias de ataque en diferentes tipos de topologías de red. Los resultados nos permitirán identificar la cantidad óptima de aleatoriedad y la elección de los parámetros del protocolo. También estamos investigando la robustez del FPC frente a fallos y perturbaciones del umbral aleatorio.
2. Los límites de la convergencia del FPC obtenidos en las simulaciones son mucho mejores que los obtenidos teóricamente por Popov y Buchanan. Diversas simulaciones de ajuste de parámetros muestran que existe el llamado «cut off phenomenon«. Informalmente, esto significa esencialmente que el protocolo necesita, por ejemplo, m pasos, con alta probabilidad de llegar a un consenso y que es muy poco probable que el protocolo necesite más que m pasos. Los resultados teóricos en esta dirección serían muy apreciados.
3. La implementación real del FPC dependerá de la reputación de los nodos. Como la reputación o maná del nodo juega un papel importante en otras partes del proyecto Coordicide, escribiremos más sobre esto en un futuro artículo en el blog. De todos modos, esta característica adicional hará que el protocolo sea más seguro contra varios tipos de ataques.
4. Los parámetros estudiados anteriormente en el FPC se establecieron en piedra al principio del protocolo. Sin embargo, para aumentar la seguridad y, al mismo tiempo, reducir la complejidad de los mensajes (lo que parece un milagro), estamos investigando versiones adaptadas del FPC. Por ejemplo, si η de un nodo está cerca de 0.5, el nodo puede decidir aumentar el número de consultas mientras que, si está cerca de 1, puede decidir reducir el número de consultas del siguiente paso o dejar de realizar consultas inmediatamente.
5. Hoy en día, el machine learning se adopta en una amplia gama de dominios donde demuestra su superioridad sobre los algoritmos tradicionales basados en reglas. Estamos planeando utilizar el machine learning, no sólo para la detección de nodos defectuosos y maliciosos, sino también para identificar las estrategias de ataque más dañinas utilizando el aprendizaje de refuerzo.
Esperamos poder llevarle con nosotros en el emocionante viaje de Coordicide a través de los ojos del departamento de Research de IOTA Foundation y esperamos que disfrute del desarrollo de este proyecto como nosotros lo hacemos.
El autor no es miembro de la Fundación IOTA. Escribió este blog en colaboración con los miembros del grupo de investigación IOTA.
Post Original: Concensus in the Tangle by Sebastian Mueller






 se une al ecosistema de Assembly")














