
Este mes, hemos visto nuevas versiones de nuestra red de pruebas Polen, así como un progreso continuo en la verificación de nuestro protocolo central mientras nos preparamos para el lanzamiento de Nectar.
Con la etapa «Nectar» de la implementación de Coordicide, nuestro equipo está realizando las últimas investigaciones que se necesitan para llevar a cabo ese hito. En este momento, el trabajo restante está relacionado principalmente con las optimizaciones, y seguiremos utilizando los datos recopilados de Pollen para implementar cualquier cambio necesario. Nectar será nuestra primera implementación de Coordicide en pleno funcionamiento, por lo que queremos hacerla lo más robusta posible desde el principio, con la vista puesta en seguir optimizandola a medida que usemos y aprendamos de la red juntos.
Además de nuestro progreso en la investigación y en la implementación de la red de pruebas, estamos muy contentos de que Billy Sanders haya asumido un papel de liderazgo como Director de Investigación. Serguei Popov seguirá desempeñando un papel muy activo en el Consejo de Administración y en la investigación diaria. Dado que Billy ya participaba en gran parte de la toma de decisiones, y que Serguei sigue activo en el departamento, esta transición ha tenido poco efecto en las operaciones del departamento. Así, nuestro equipo ha continuado este mes haciendo progresos en todos los frentes.
A continuación se presentan las actualizaciones de nuestros diversos grupos de investigación:
Implementación de Pollen Testnet. El equipo ha lanzado dos versiones, v0.3.6 y v0.4.0, completando la refactorización de la Tangle con la fusión del Value Tangle y la introducción de componentes mejorados como el solidificador, el ledgerstate, el booker, el opinion former así como el nuevo scheduler que forman parte del nuevo flujo rediseñado en el núcleo del protocolo Coordicide.
Como se presentan en las notas sobre el lanzamiento de la testnet de Pollen, cada componente puede verse como una caja negra, y la interacción entre ellos se produce a través de eventos. Precisamente, el flujo comienza desde el gossip o el MessageFactory. Luego, el Parser se encarga de validar la estructura de los mensajes. El componente de Storage almacena los mensajes así como sus metadatos en la BD, y crea la estructura de Tangle. El solidificador se asegura de solicitar todos los mensajes que faltan, y garantiza que el Tangle crezca monotónicamente en términos de timestamps de los mensajes.
El Scheduler programa los mensajes que luego pasan al Booker y se reservan. Si un mensaje contiene una transacción como carga útil, el Booker ejecuta una secuencia de comprobaciones (por ejemplo, validez de la firma, validez del saldo, doble gasto) y contabiliza la transacción en la realidad correspondiente. El OpinionFormer determina la opinión del mensaje y de la carga útil con FCoB y ejecuta la votación mediante FPC (Fast Probabilistic Consensus) si es necesario. Por último, en función del resultado de la opinión del mensaje y de su condición de cono pasado, los mensajes deseados se añaden al conjunto de Tips débiles o fuertes, respectivamente.
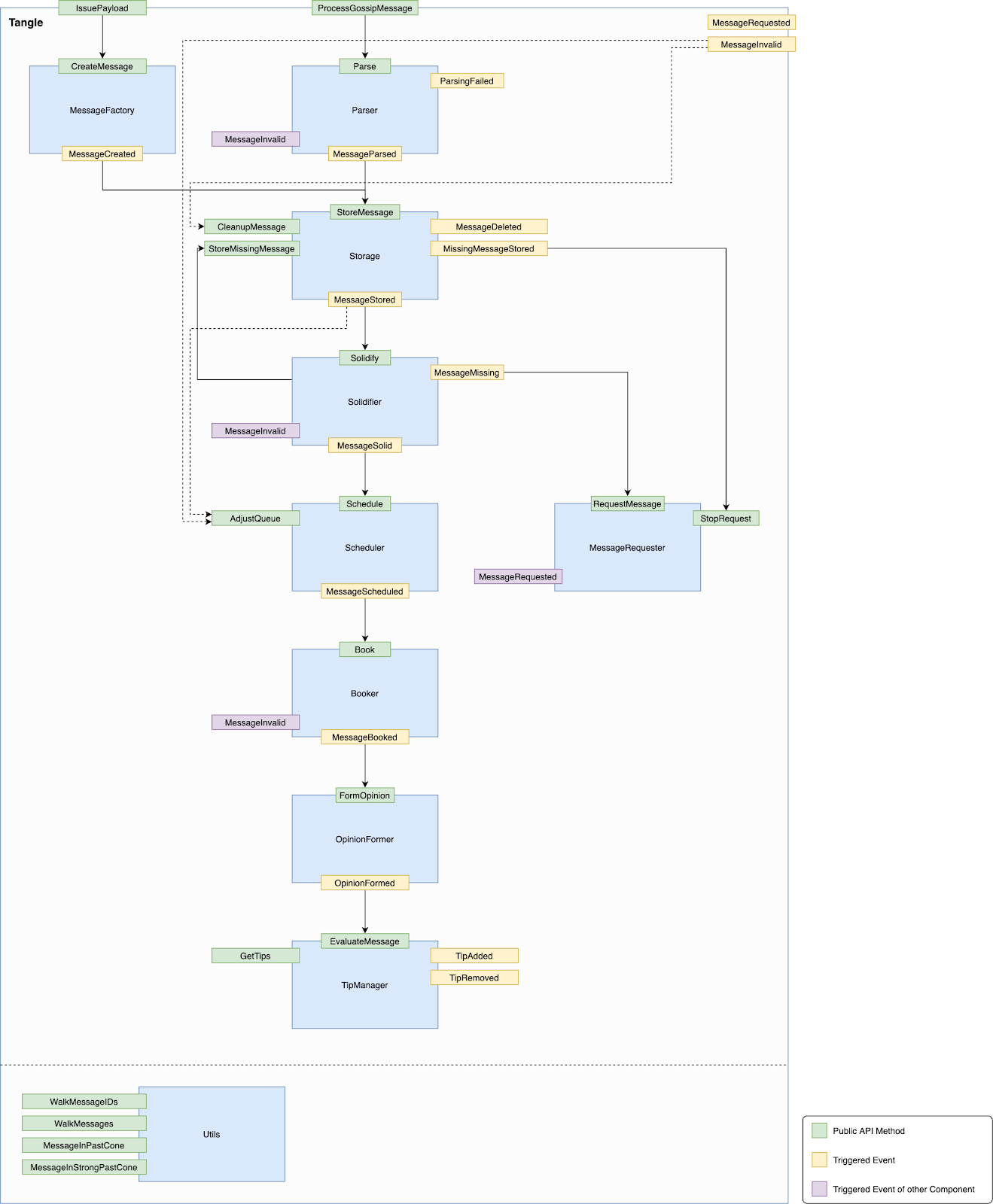
Estos cambios, así como las nuevas optimizaciones, nos permiten avanzar en la integración del mana en nuestro prototipo.
En concreto, el mana se integrará en pasos incrementales. La versión inicial contendrá mana de acceso y de consenso, pero ninguno de los módulos lo utilizará. Las herramientas de visualización y análisis nos permitirán estudiar primero su dinámica y conocer su distribución en la testnet. Este es un paso importante para ajustar sus parámetros y empezar a integrarlo en los distintos componentes, como por ejemplo para el control de la congestión, el consenso, la finalidad y el dRNG.
Protocolo. El grupo de protocolo utiliza ahora sus recursos para gestionar el progreso del proyecto de las nuevas especificaciones, que nace de los esfuerzos en la elaboración de un borrador que se inició el año pasado junto con la nueva investigación desarrollada desde entonces. Seguiremos realizando y compartiendo algunas investigaciones, pero de forma menos frecuente, ya que la mayoría de nuestros problemas teóricos se han resuelto.
El mes pasado el grupo trabajó en el problema del «Number of Parents». Durante un tiempo, hemos considerado la idea de aumentar el número de aprobaciones que hace un mensaje desde 2 a un valor mayor k. Estamos considerando cómo esto puede afectar a la tasa de orfandad, al tiempo de finalidad y a la posibilidad de que un usuario muy fuerte que utilice muchos nodos (para saltarse la defensa del rate control) intente llevar a cabo un ataque de aprobación que infle la orfandad artificialmente. Todavía estamos estudiando otras perspectivas, pero afortunadamente el aumento de aprobaciones es extremadamente efectivo contra este tipo de ataque. ¡Esperamos tener un documento adecuado con todos los estudios y simulaciones que estamos haciendo sobre esto para la próxima actualización!
Especificaciones. Ha pasado algún tiempo desde que se hizo el primer borrador de las especificaciones, y la investigación sobre Coordicide ha evolucionado para conseguir que el sistema sea más sencillo y robusto. Entre los cambios importantes podemos citar la fusión del Message Tangle con el Value Tangle, la creación del enfoque de interruptor de aprobación (switch approach), la definición de la métrica del peso de la aprobación (weight metric) (una nueva herramienta que utiliza la antigua fiabilidad de la confirmación y el mana para determinar la finalidad), la introducción de marcadores y épocas, así como el refinamiento de muchos componentes.
Todo esto nos dio la señal de que, junto con la experiencia del primer borrador del año pasado, era el momento de volver a las especificaciones y hacer algo que esté listo para ser compartido con la comunidad, obtener una validación externa, así como vetar de acuerdo con otros criterios rigurosos de normalización.
Al comienzo de este proyecto, tuvimos que reestructurar los componentes que formarán parte del Coordicide, y decidimos sobre los escritores, los plazos y la metodología. Ahora todo el mundo lo está poniendo todo de sí para conseguir un resultado de mucha más calidad. Esperamos tener algo para compartir con todos en la próxima actualización.
Grupo de estudio de la Tesnet de Pollen. El último mes nos reveló una vez más que escribir trabajos académicos no es sólo un ejercicio de «escribir un papel», sino que es útil para aclarar pensamientos y nos ayuda sobre la comprensión de un tema. En nuestro ejemplo, empezamos a redactar el trabajo de investigación sobre nuestra propuesta de autopeering. Durante las fructíferas discusiones y el cuestionamiento de todos los elementos, no sólo obtuvimos una comprensión mucho mejor, sino que también propusimos mejoras. Además de esta tarea centrada en la investigación, durante este último mes hemos seguido analizando la aplicación actual y hemos identificado algunos problemas menores que sobre los cuales ya estamos trabajando.
Networking. Este mes evaluamos el impacto de los cambios de mana en el mecanismo de control de congestión. Las simulaciones muestran que nuestro algoritmo reacciona rápidamente a estos cambios cuando el maná se calcula según una media móvil. Sin embargo, cuando el maná disminuye repentinamente, la longitud de la bandeja de entrada del nodo, calculada según el maná, aumenta en consecuencia.
Dado que la longitud de las bandejas de entrada es la métrica clave para la inclusión en la lista negra de comportamientos maliciosos, actualmente estamos diseñando una forma que garantice que no se produzcan falsos positivos en la lista negra de nodos honestos.
Además, nos complace anunciar que la ponencia «Access Control in Adversarial Environments for IoT-oriented Distributed Ledgers» ha sido aceptada para ser presentada en el 7º workshop IEEE/IFIP sobre Seguridad para Tecnologías de Redes Distribuidas Emergentes (IM 2021/DISSECT). El artículo describe nuestro algoritmo de control de la congestión que se utilizará en IOTA 2.0 («Coordicide»).
Sharding. Como ya comentamos en la anterior actualización, actualmente estamos trabajando en el whitepaper, antes de hacer un anuncio más formal sobre el tema. Al escribir este documento, estamos completando los detalles de de esta solución y comprendiendo mejor los desafíos fundamentales. Por ejemplo, ya tenemos una idea mucho mejor de cómo modelar el posible rendimiento que permitirá la solución de sharding respecto a los datos. El sharding de datos parece ser una solución robusta contra todos los vectores de ataque que hemos discutido. La simplicidad de la solución permitirá que sea flexible y la implementación será, relativamente mucho más fácil que, por ejemplo, Coordicide.
Artículo original: IOTA Research Update



 – La era de la descentralización de IOTA comienza aquí")
 al mana de IOTA")

















